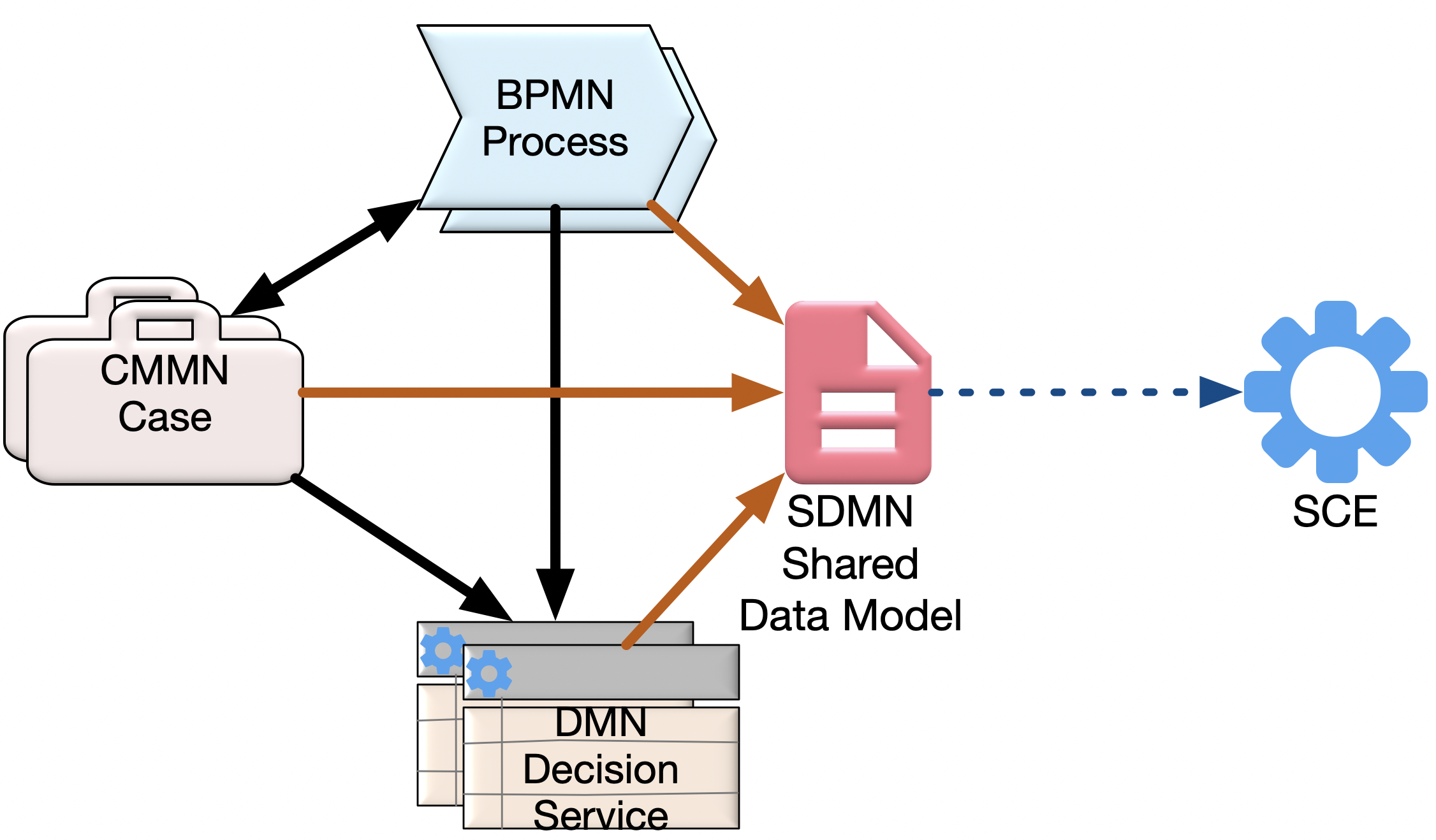
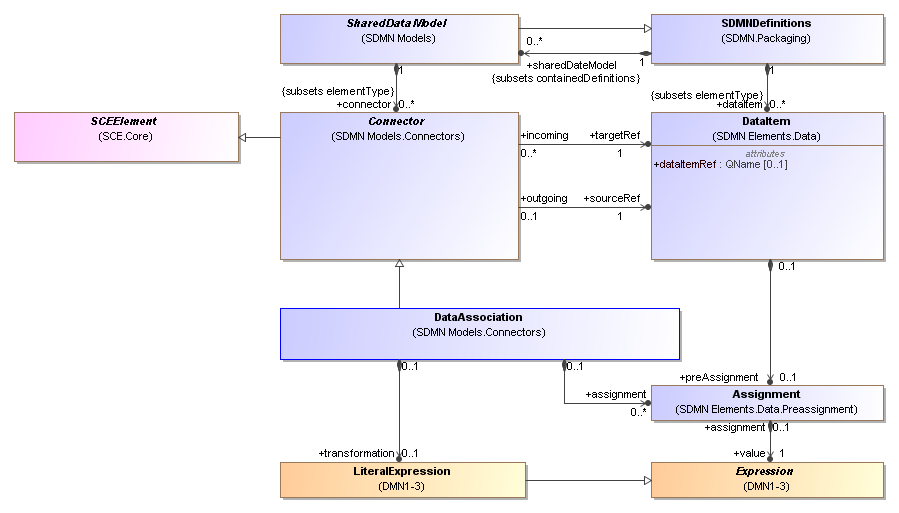
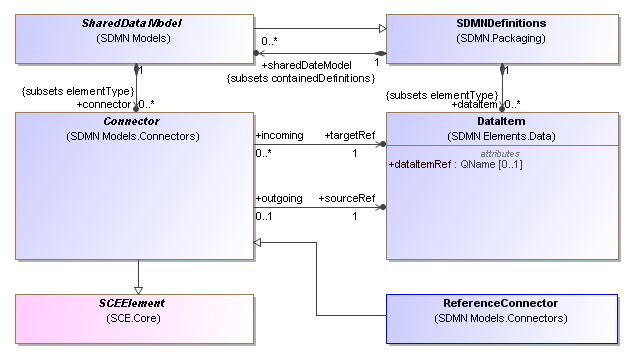
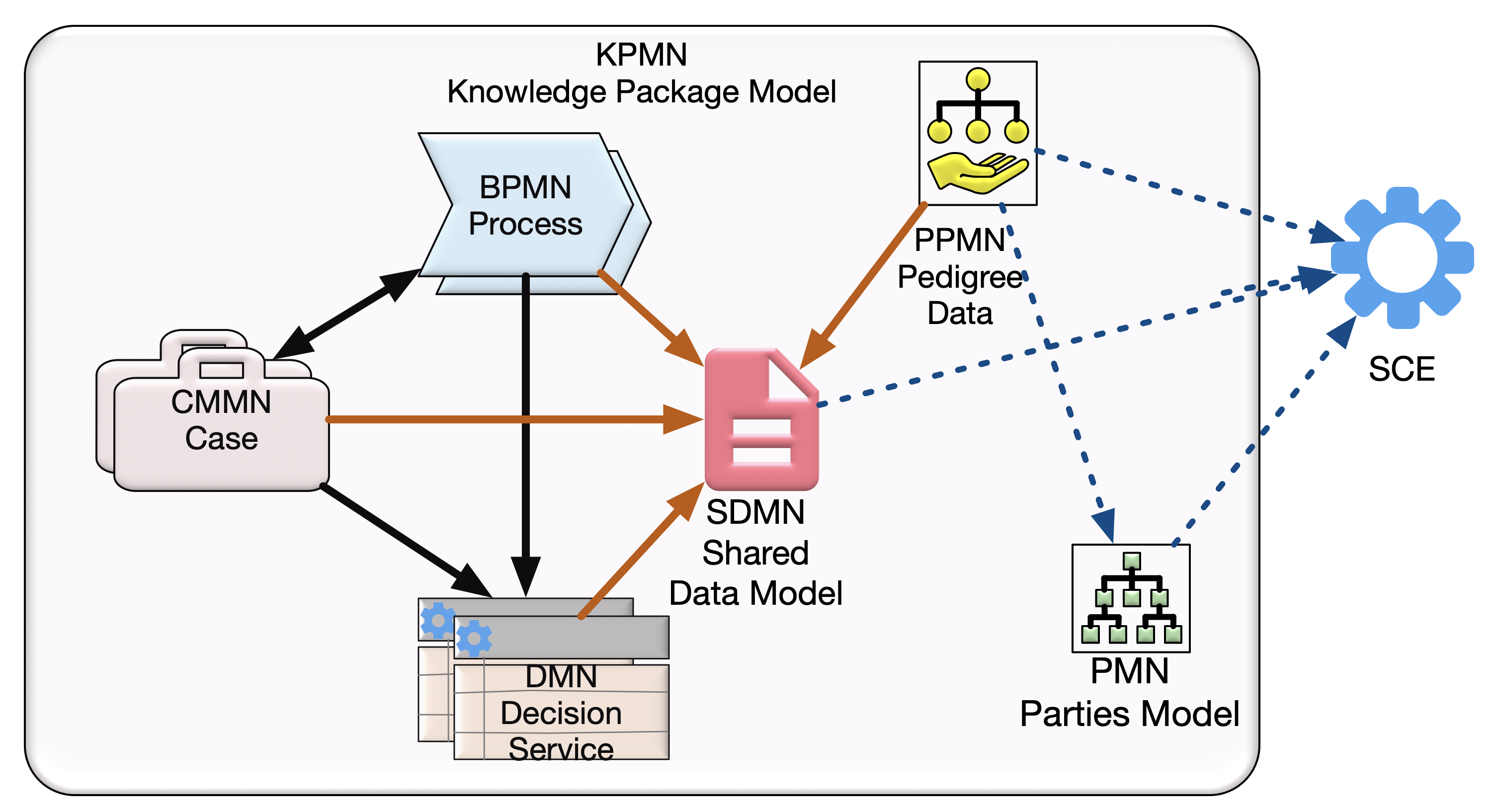
The file filed as the SCE metamodel is in fact SDMN
-
Key: SCE-88
-
Status: closed
-
Source: Adaptive ( Mr. Pete Rivett)
-
Summary:
This file linked to from the SCE catalog page (https://www.omg.org/spec/SCE )
https://www.omg.org/spec/SCE/20211101/SCE.xmi does not include the SCE package but seems to be the SDMN package which imports SCE (there are proprietary hrefs to SCE.mdzip) though the file has more than the official SDMN metamodel.Further the files on this catalog page https://www.omg.org/spec/SCE which have SCE in their name have descriptions which refer to SDMN not SCE e.g.
"Shared Data Model and Notation (SDMN) XSD" is the description for SCE/20211101/SCE-Library.xsd -
Reported: SDMN 1.0b1 — Mon, 22 Aug 2022 06:29 GMT
-
Disposition: Closed; Out Of Scope — SCE 1.0b2
-
Disposition Summary:
Out of scope for the FTF
The FTF is not is a position to correct this issue. The correct files have been submitted to the OMG for replacement on the web site. Furthermore, we will ensure that the proper updated files are submitted at the completion of this FTF.
-
Updated: Mon, 16 Sep 2024 14:12 GMT
-
Attachments:
- bmi-21-11-25.xsd 2 kB (text/xml)
- bmi-21-11-26.xsd 60 kB (text/xml)
- bmi-21-11-28.xml 2 kB (application/xml)
- bmi-21-11-29.xsd 5 kB (text/xml)
- bmi-21-11-45.xml 243 kB (application/xml)
- bmi-21-11-47.xml 96 kB (application/xml)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}