Incorrect claim about the Unicode character range and EBNF character expressions
-
Key: DMN13-127
-
Status: closed
-
Source: Fujitsu ( Keith Swenson)
-
Summary:
This is a trivial typo, and the fix is easy.
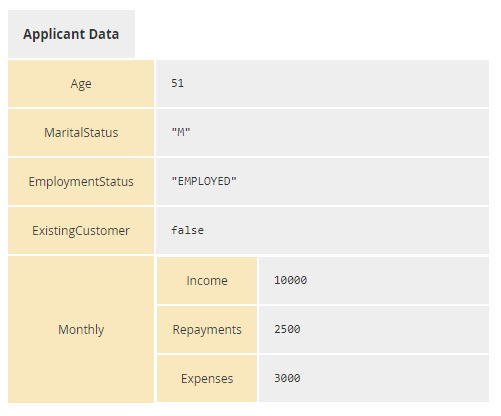
Lower on page 108 it says: "the character range that includes all Unicode characters is [\u0-\u10FFF]." This range specified has less than 70,000 characters.
I don't think your intent is to limit implementations to 70K characters and in fact in places (e.g. grammar rule #30) character values larger than this are mentioned.
"all Unicode characters" is actually the entire range of 32-bit values (minus some control codes: hundreds of millions of characters, most of which are undefined). Instead you are defining a SUBSET of this that will be allowed.
Second, the most common implementation of Unicode uses UTF-16, and as a consequences OF THIS ENCODING, the range of representable characters is 0 through 10FFFF. Note that is six hex digits, there are four F digits. There are over a million characters in this range.
(1) Nowhere in the spec does is say you are limiting characters to the UTF-16 range. This should be explicitly stated if that is your intent.
(2) The phrase on page 108 should be changed to; "DMN allows the use of unicode characters in the range of [\u0-\u10FFFF]."
(3) The specification of EBNF character expression should be changed to allow 6 hex digits, currently it says you can only use five digits max.
-
Reported: DMN 1.2b1 — Mon, 31 Dec 2018 17:00 GMT
-
Disposition: Resolved — DMN 1.3
-
Disposition Summary:
Allow 4 or 6 hexadecimal digits for unicode code point
See attached word doc
-
Updated: Tue, 26 Jan 2021 20:17 GMT
-
Attachments:
- DMN13-127-v7.docx 19 kB (application/vnd.openxmlformats-officedocument.wordprocessingml.document)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}