UML Model is not consistent with document and missing types
-
Key: DDSXTY12-149
-
Status: closed
-
Source: Real-Time Innovations ( Dr. Gerardo Pardo-Castellote, Ph.D.)
-
Summary:
This changes are needed to align the XTYPES model with IDL4. Specifically with regards to annotations.
In IDL4 it is possible to annotate type declarations, members, and elements in a collection as in:
@MyAnnotation(3) struct MyStruct { @MemberAnnotation long l_member; sequence< @ElementAnnotation long, 55> seq_member; };Union discriminators can also be annotated and so can members, but not the case literals:
@MyAnnotation(3) union MyUnion switch ( DiscriminatorAnnotation(44) long) { case 1: @MemberAnnotation long l_member; default: sequence< @ElementAnnotation long, 55> seq_member; };
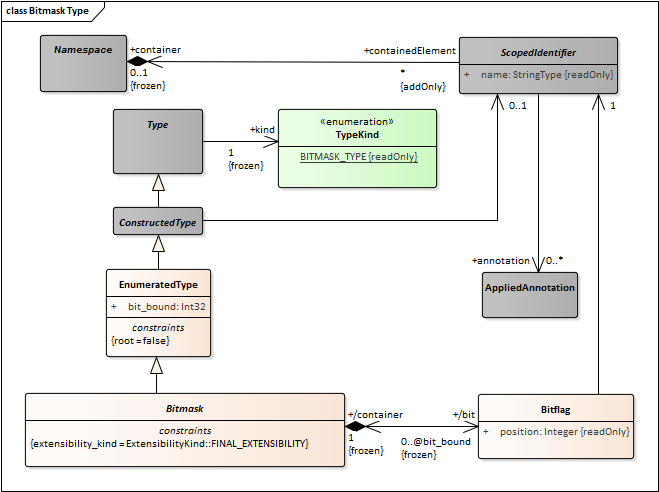
It is also possible to annotate enumeration, bitmask and bitset members.
@MyAnnotation(3) bitmask MyBitmask{ @position(2) flag1; };Annotation are also permitted in the “related type” for a typedef:
typedef @max(23) long MyLong; typedef sequence<@external long> LongPtrSeq;
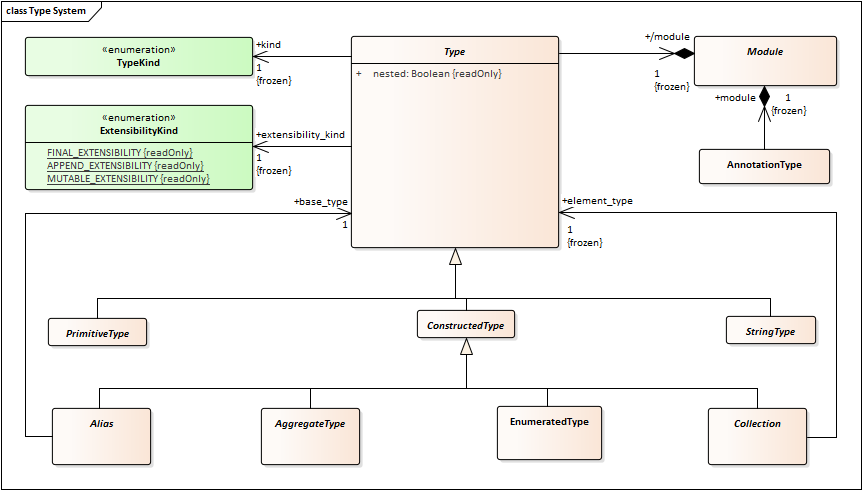
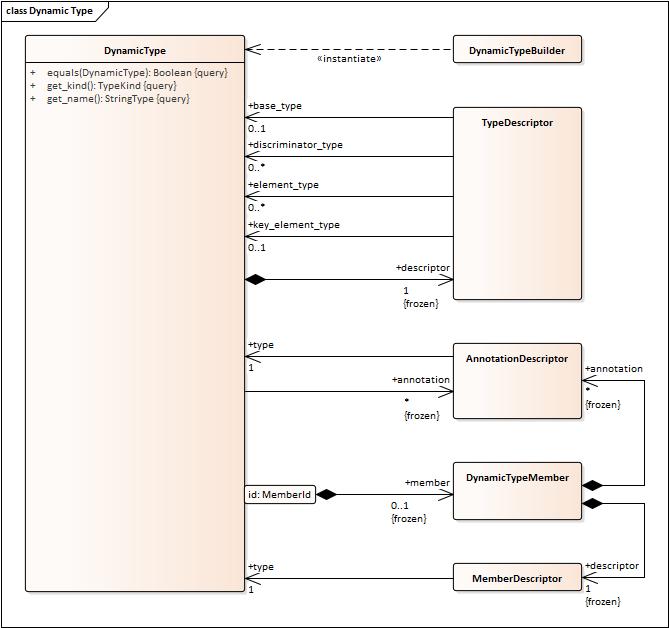
Another issue is that in the new XTYPES we are no longer requiring that all types are named. So that the inheritance of Type from NamedElement is not what we want.
Currently we use NamedElement model both the name of a type as well as the name of a member (structure, union), name of a bitflag, module, and enum literal.
Those are things we want to annotate. But we also want to annotate element of a collection as well as the discriminator of unions which have no name.
-
Reported: DDS-XTypes 1.1 — Fri, 20 Jan 2017 10:49 GMT
-
Disposition: Resolved — DDS-XTypes 1.2
-
Disposition Summary:
Update UML Model to align it with IDL4
This changes are needed to align the XTYPES model with IDL4. Specifically with regards to annotations.
In IDL4 it is possible to annotate type declarations, members, and elements in a collection as in:
@MyAnnotation(3) struct MyStruct { @MemberAnnotation long l_member; sequence< @ElementAnnotation long, 55> seq_member; };Union discriminators can also be annotated and so can members, but not the case literals:
@MyAnnotation(3) union MyUnion switch ( DiscriminatorAnnotation(44) long) { case 1: @MemberAnnotation long l_member; default: sequence< @ElementAnnotation long, 55> seq_member; };
It is also possible to annotate enumeration, bitmask and bitset members.
@MyAnnotation(3) bitmask MyBitmask{ @position(2) flag1; };Annotation are also permitted in the “related type” for a typedef:
typedef @max(23) long MyLong; typedef sequence<@external long> LongPtrSeq;
Another issue is that in the new XTYPES we are no longer requiring that all types are named. So that the inheritance of Type from NamedElement is not what we want.
Currently we use NamedElement model both the name of a type as well as the name of a member (structure, union), name of a bitflag, module, and enum literal.
Those are things we want to annotate. But we also want to annotate element of a collection as well as the discriminator of unions which have no name.
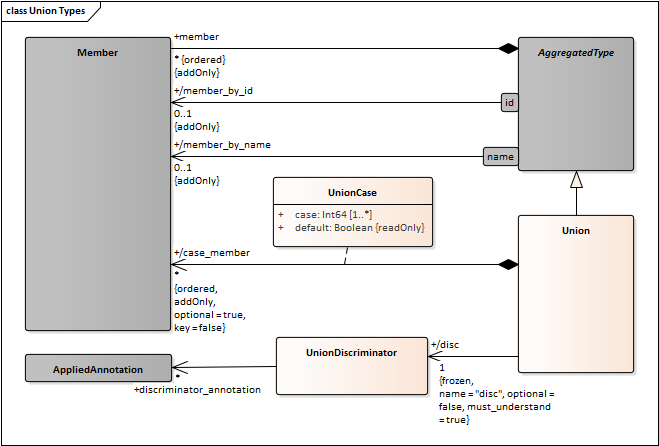
Modifications to the UML model
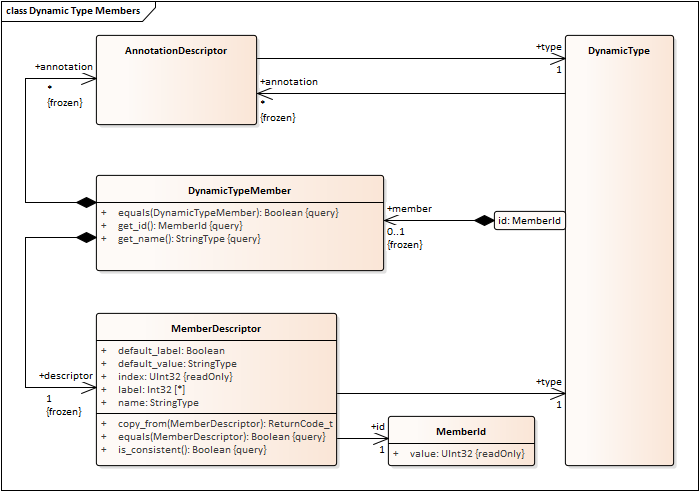
The UML model needs an AppliedAnnotation class that models the application of annotations to some other classifier.
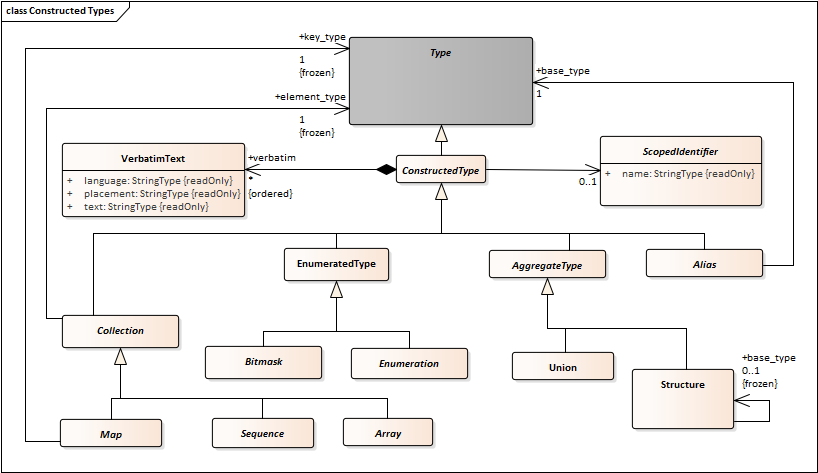
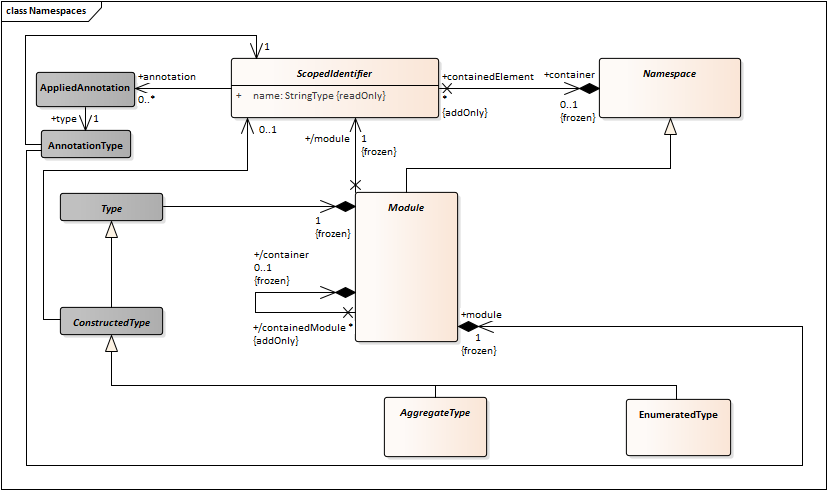
Also NamedElement should not be modeled as a “base class” but rather as something that certain classifiers have. So it should be a “has-a” relationship. That would allow some types (e.g. anonymous types) to not have a name.
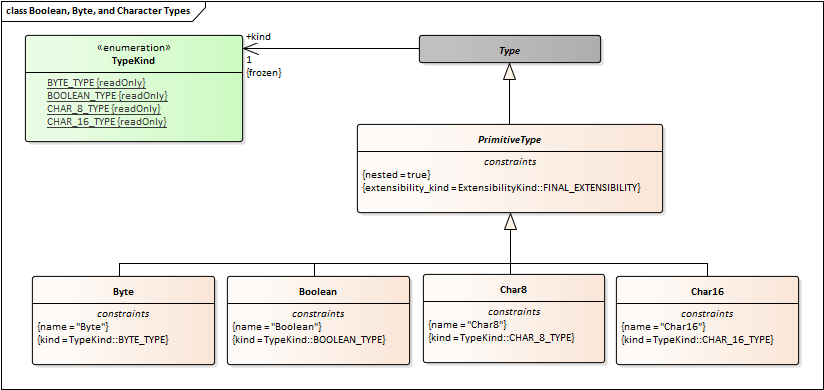
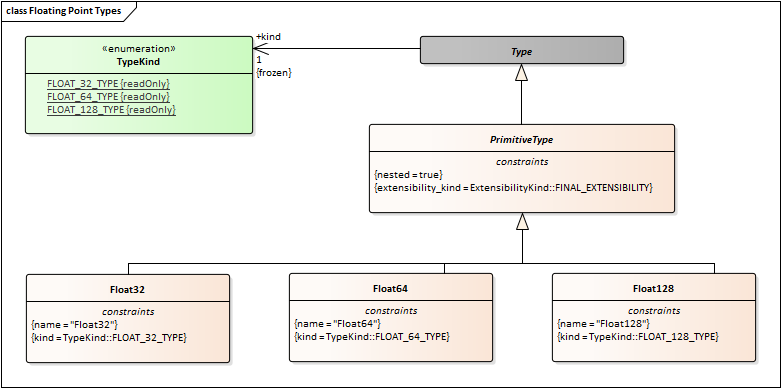
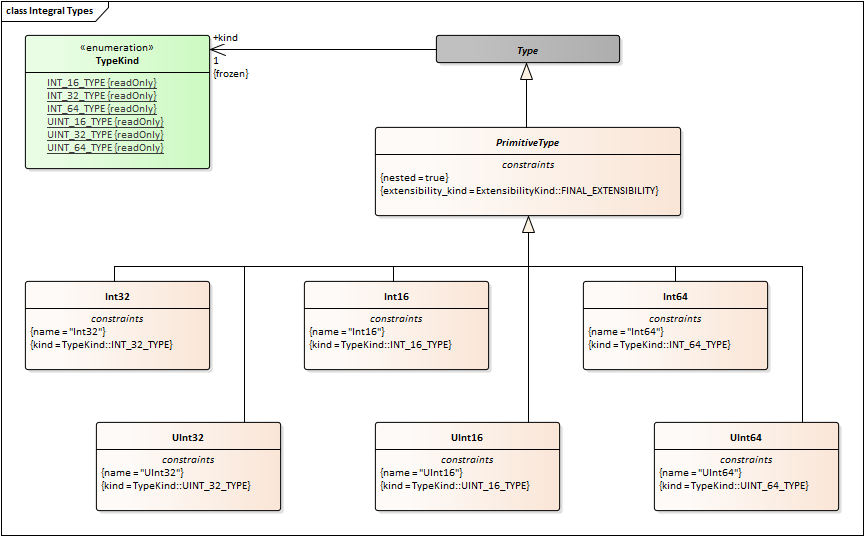
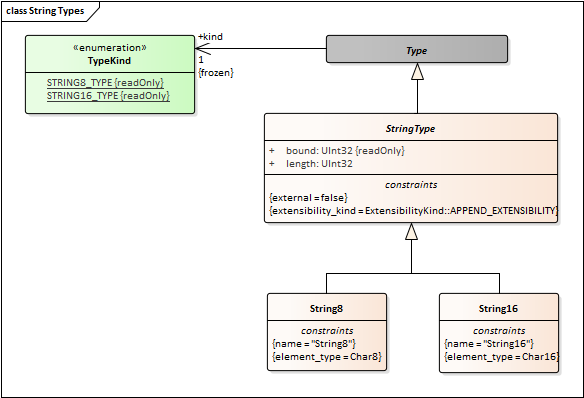
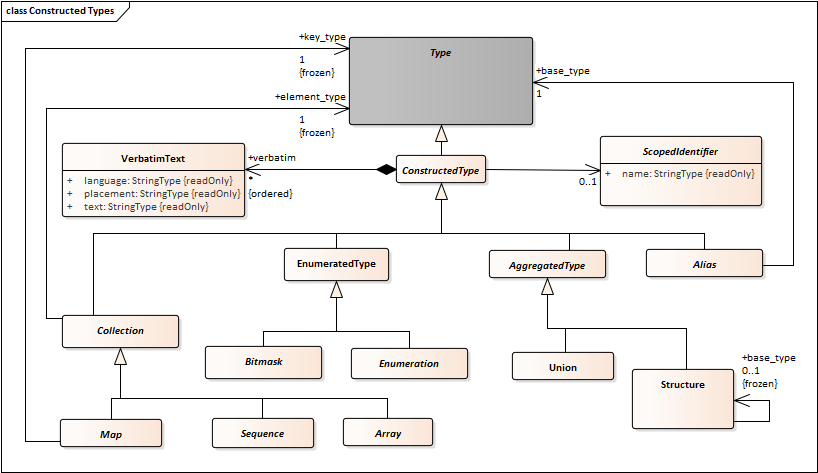
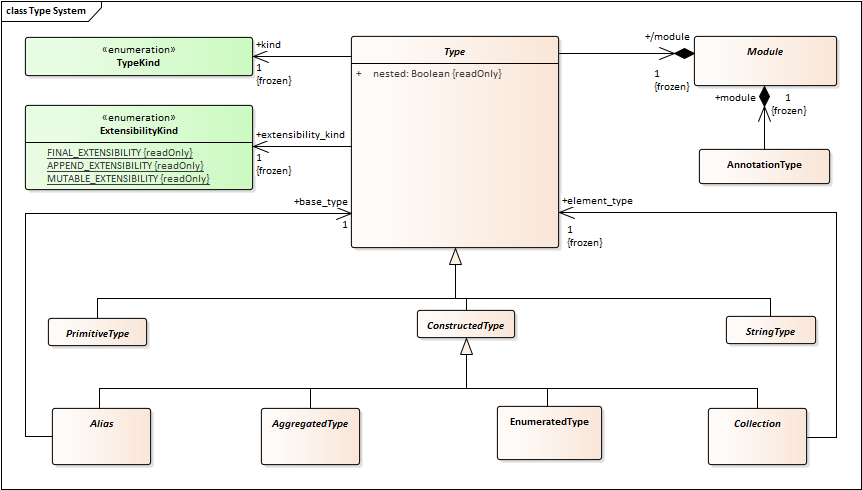
String should not inherit from Collection. There should be a StringType that is specialized by String8 and String16. StringType would be a direct child of Type, peer to PrimitiveType.
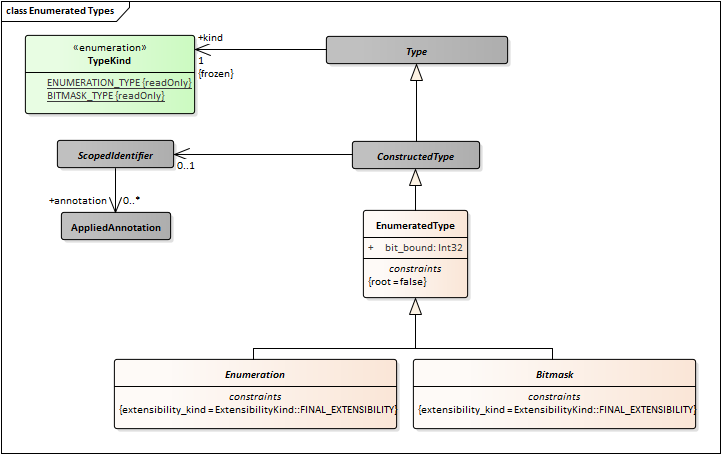
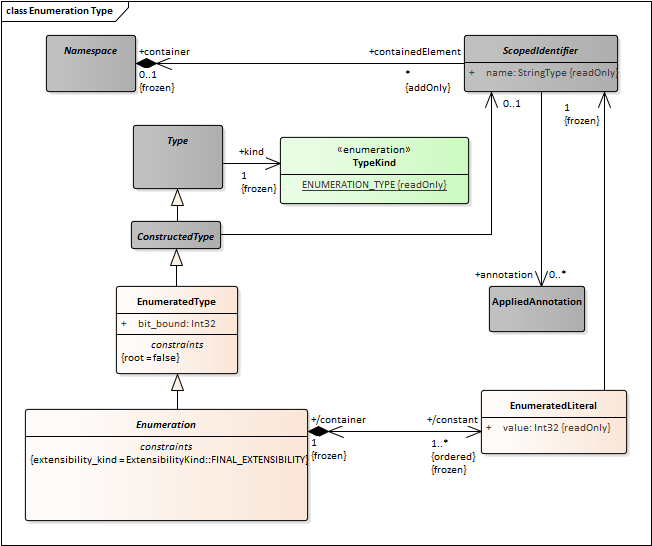
There should be a EnumeratedType peer of PrimitiveType. It should have Enumeration and Bitmask as specializations.
Bitset should be added as another specialization of Aggregation.
In addition:
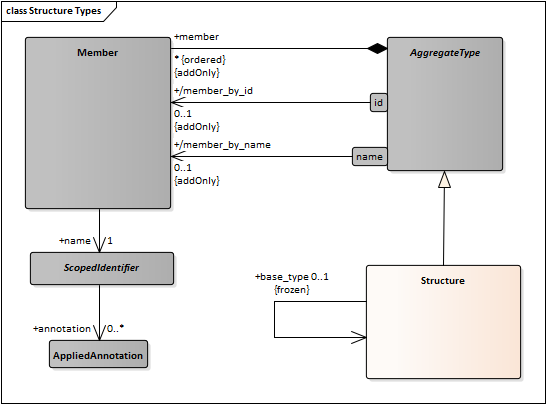
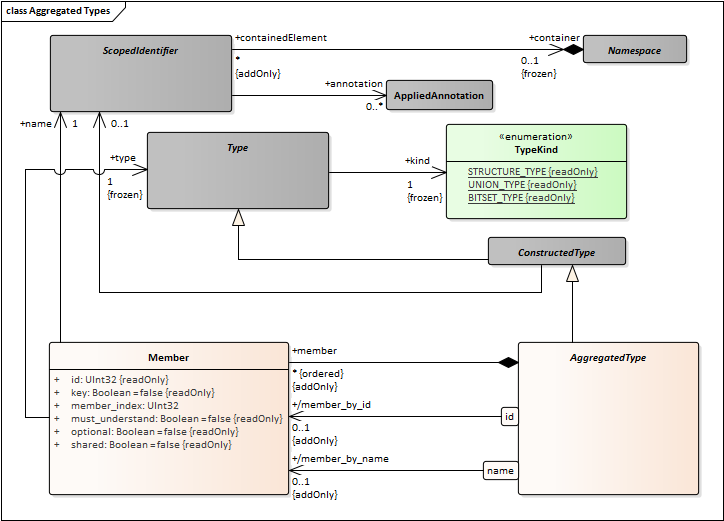
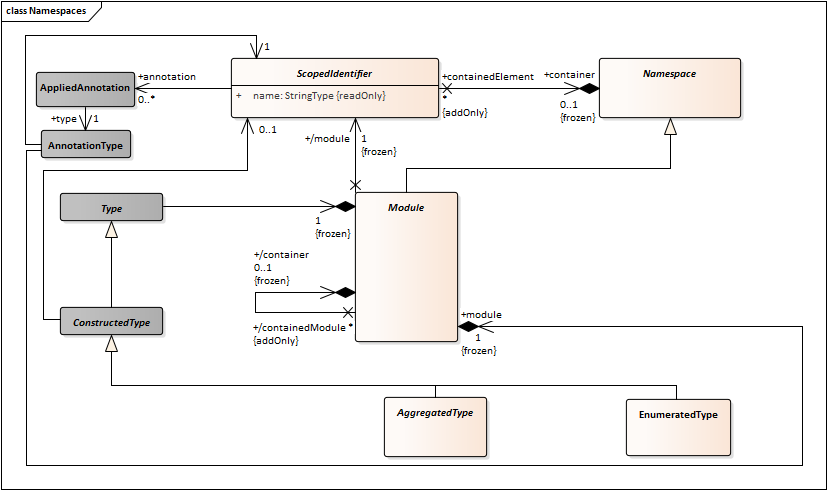
- Create an association between Aggregation and NamedElement. This has cardinality “1”. Every Aggregation type has a name.
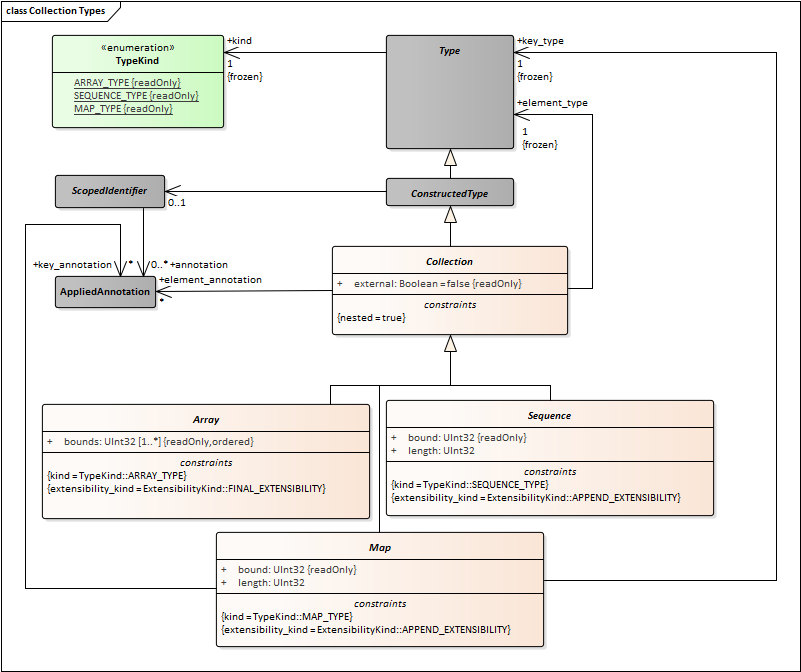
- Create an association between Collection and NamedElement. This has cardinality “0..1”. Collection types can be named or anonymous.
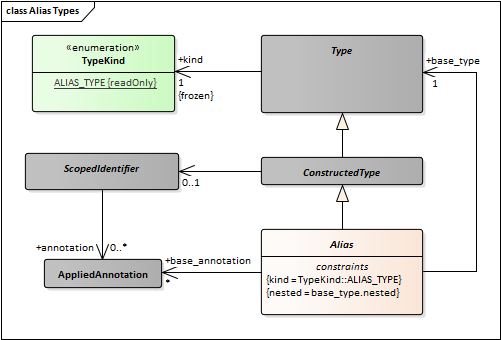
- Create an association between Alias and NamedElement. This has cardinality “1”. Alias types always have a name.
- Add an association between ConstructedType and NamedElement. It should have to be “0..1” to capture the possibility for anonymous collections.
- Module, EnumerationLiteral, Bitflag, Member, and Bitfield would also have a “has-a” relation to NamedElement with cardinality “1”.
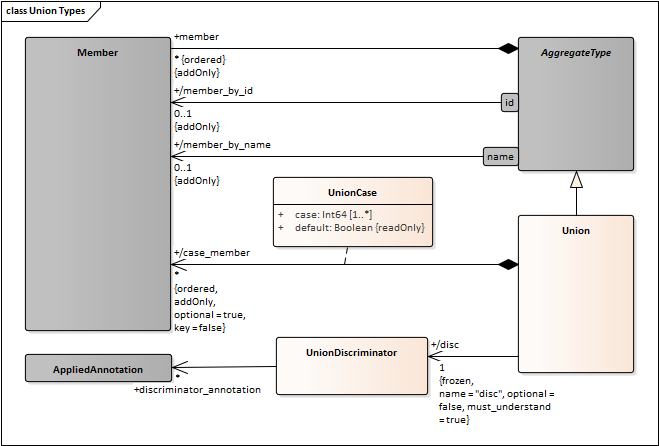
- Model the annotations on collection element and union discriminator.
- Union Discriminator requires a separate class. Currently it is modeled as a “member” but that is odd (e.g. it is unnamed, has hard-coded memberID) better to model it separately.
- Change NamedElement to ScopedIdentifier.
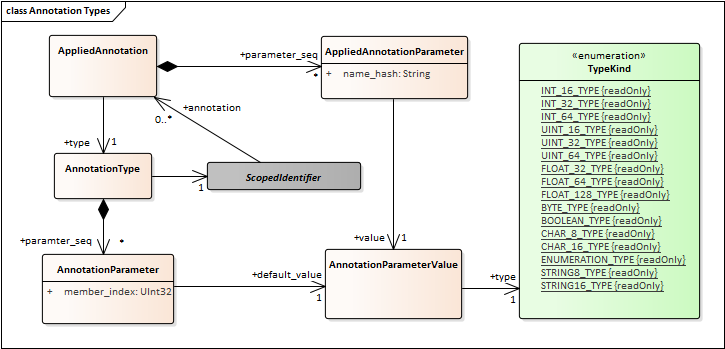
Enhance model for Annotations
Currently Annotation specializes Aggregation type. This is wrong in several ways.
Al constructed types can be annotated. But Annotations cannot have annotations.
It does make sense to talk about the extensibility kind of an annotation. Nor about the type compatibility/assignability.Many associations to type (e.g. a structure member has a type) do not make sense if the “type” is an annotation.
The only thing from Type is that they can have a type object.
Annotations should not be modeled as types. They should not specialize “Type” they should be their own thing. Basically we define a AnnotationDeclaration an AppliedAnnotation (and AnnotationParameter). This can follow the TypeObject model.
Then section 7.2.2.3.6 “Annotation Types” can be moved to a higher level. Say 7.2.2.6 after :”Try Construct Behavior”
Also in the XTYPES it says (in section 7.2.2.3.6) that annotations can inherit from other annotations. However the IDL grammar 7.4.15 does not support annotation inheritance so we should get rid of that in the XTYPES.
-
Updated: Thu, 22 Jun 2017 16:42 GMT
-
Attachments:
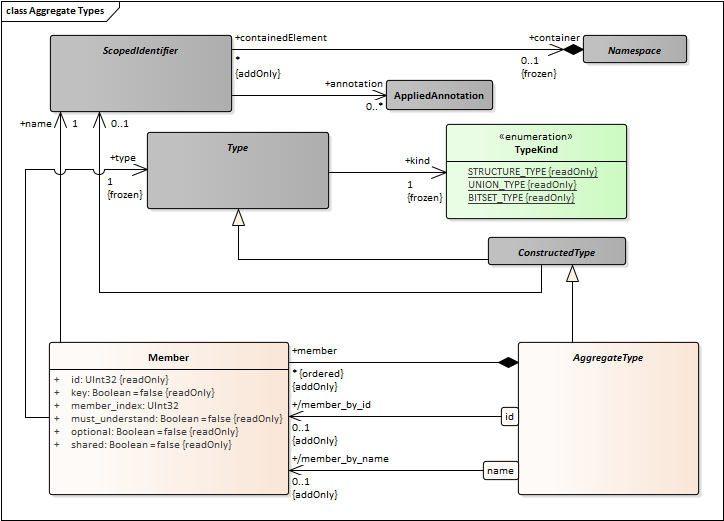
- Aggregate Types.emf 83 kB ()
- Aggregate Types.png 38 kB (image/png)
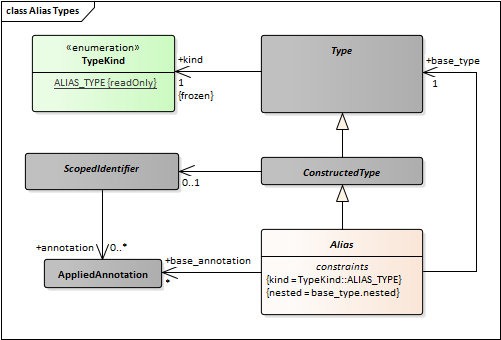
- Alias Types.emf 48 kB ()
- Alias Types.png 19 kB (image/png)
- Annotation Types.emf 84 kB ()
- Annotation Types.png 42 kB (image/png)
- Bitmask Type.emf 81 kB ()
- Bitmask Type.png 33 kB (image/png)
- Boolean, Byte, and Character Types.emf 58 kB ()
- Boolean, Byte, and Character Types.png 27 kB (image/png)
- Collection Types.emf 90 kB ()
- Collection Types.png 47 kB (image/png)
- Constructed Types.emf 144 kB ()
- Constructed Types.png 34 kB (image/png)
- Enumerated Types.emf 65 kB ()
- Enumerated Types.png 26 kB (image/png)
- Enumeration Type.emf 82 kB ()
- Enumeration Type.png 35 kB (image/png)
- Floating Point Types.emf 50 kB ()
- Floating Point Types.png 23 kB (image/png)
- Integral Types.emf 75 kB ()
- Integral Types.png 33 kB (image/png)
- Namespaces.emf 93 kB ()
- Namespaces.png 29 kB (image/png)
- String Types.emf 50 kB ()
- String Types.png 22 kB (image/png)
- Structure Types.emf 47 kB ()
- Structure Types.png 17 kB (image/png)
- Type System.emf 114 kB ()
- Type System.png 34 kB (image/png)
- Union Types.emf 61 kB ()
- Union Types.png 23 kB (image/png)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}