Revise the specification for datatypes in general
The approach taken to representation of datatypes in UML proved to be less than satisfactory from an implementation perspective, and has been substantially revised via this issue.
The critiques can be grouped in three (plus one) categories:
- (a) The use of UML tooling. The original specification was built using a tool (UMLDesigner) which is based on the Eclipse UML framwork. Moreover, UMLDesigner development has been abandoned, rasining concerns of compatibility and sustainability.
- (b) The use of UML modeling constructs. We have used UML for a very specific purpose: defining datatypes ("structures") used for transport of information at the API layer.
The specification of operations, domain specific conceptualizations and classes/components designed for the internal implementation of Knowledge Platform services has been done in different models, or left out of scope. The intent of the datatype model, instead, has been to provide a core PIM model that could be easily mapped to a variety of PSM frameworks.
As it turned out during implementation, the intersection of the most common PSM frameworks is fairly narrow, For example, IDL datatypes do not support (multiple) implementation inheritance, but require the use of type inheritance via interfaces instead. JSON schemas can emulate (multple) implementation inheritance via 'allOf', but multiple inheritannce is not supported in XML schemas... Similar issues arise when using certain primitiive datatypes, or trying to enforce certain schema constraints.
- (c) The completeness of the model. Since the original revision, certain datatype (or elements thereof) have turned out to be more useful than others. Conversely, other datatypes turned out to be underspecified, such as "Error".
- (d) The documentation of the model was generally lacking details
All things considered, it was deemed appropriate to revise the datatypes altogether. The API / datatype boundaries have been left mostly untouched, with the exception of some consolidations detailed below. Instead, the bulk of the work has focused on reshaping the internal details. In doing so, we have taken into account emergent standards and best practices which did not exist at the time of the original specification.
More specifically, to address the critique points:
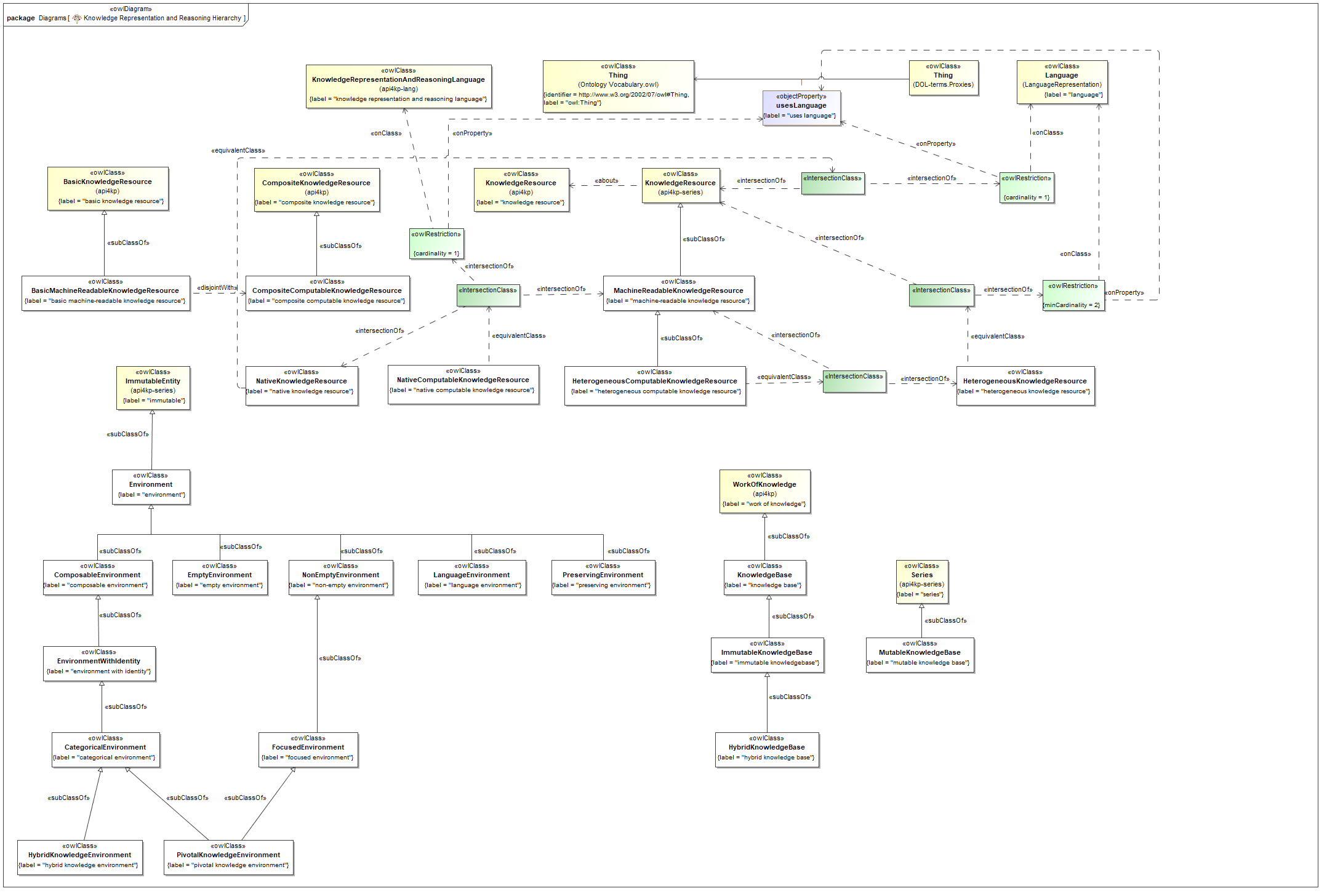
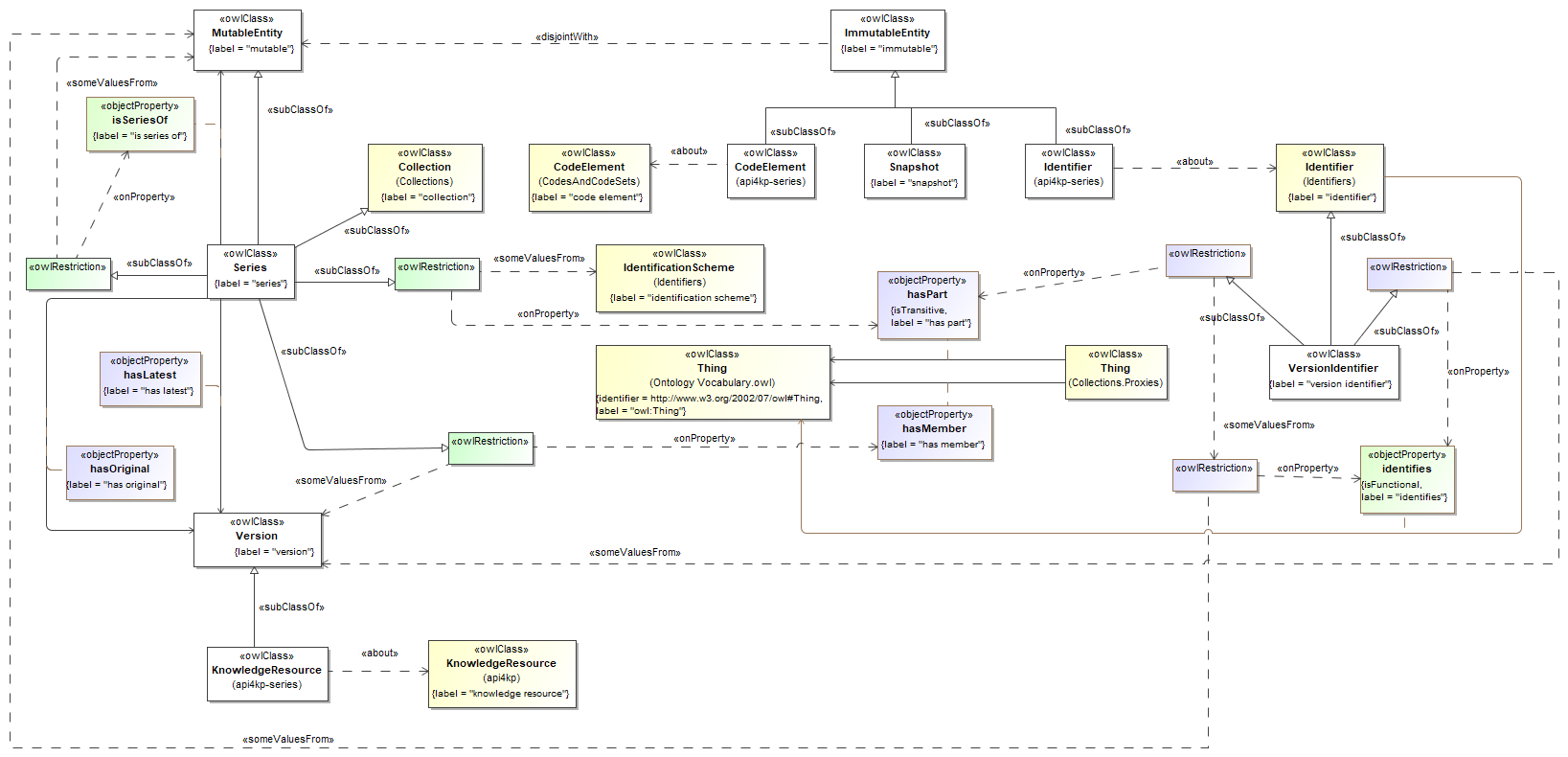
- (a) We have rebuilt the datatype model as a UML 2.5.x model using MagicDraw. The model has then been exported as a 'clean XMI' document for portability
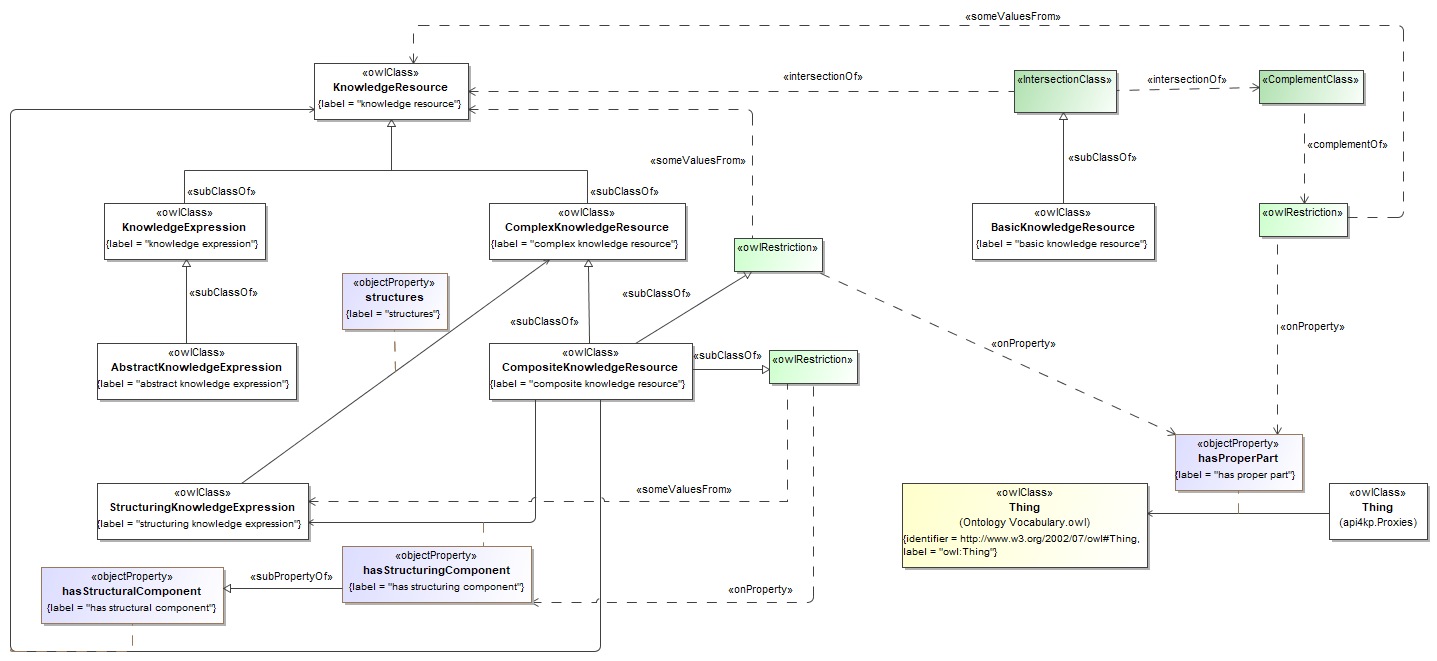
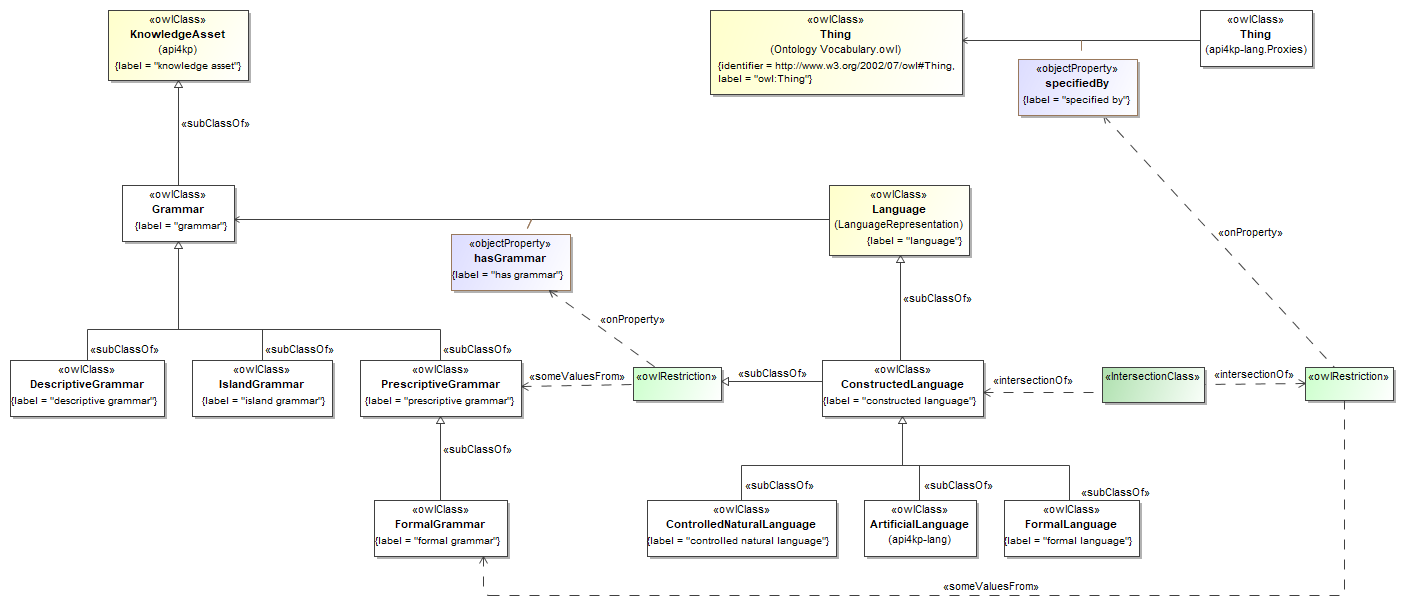
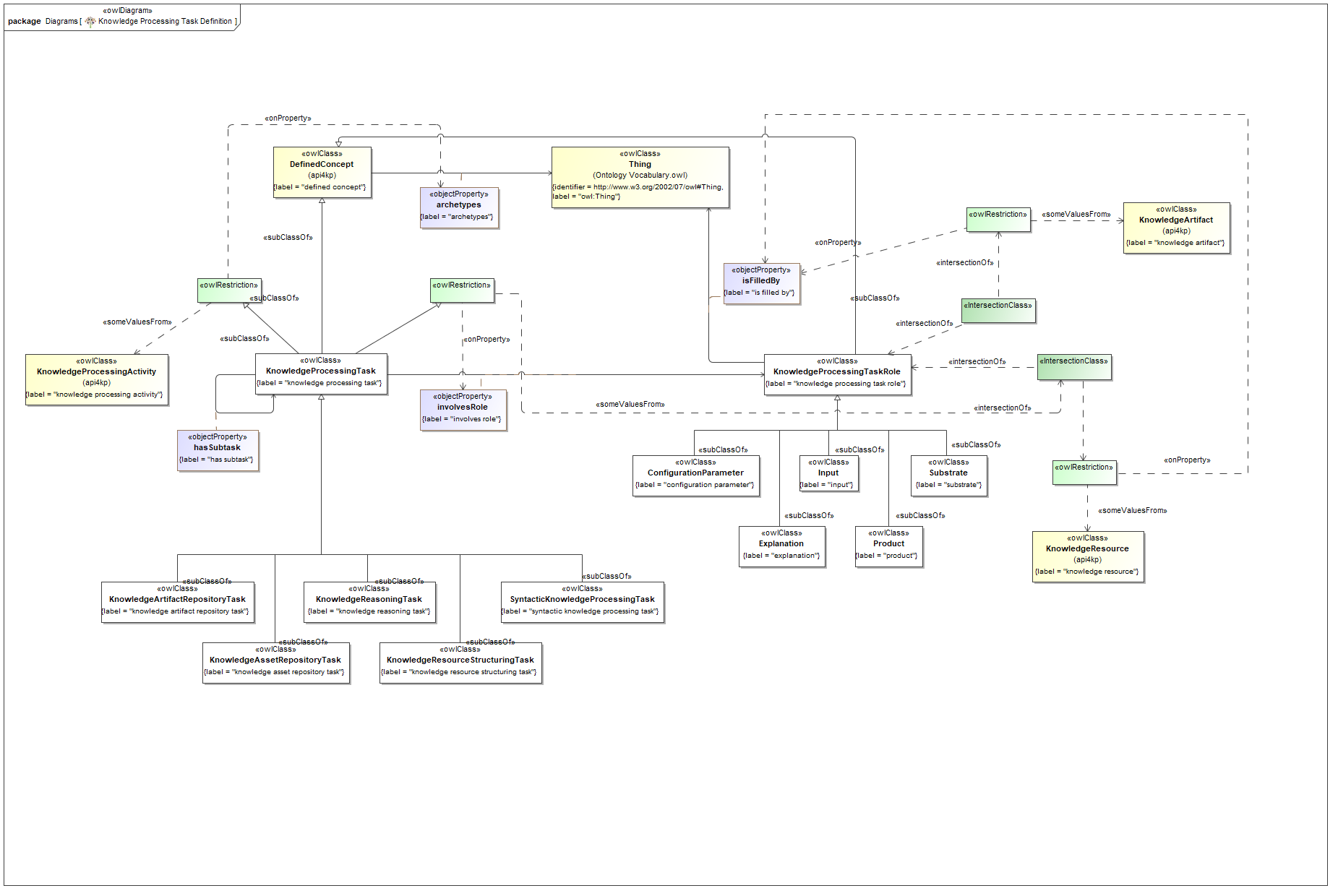
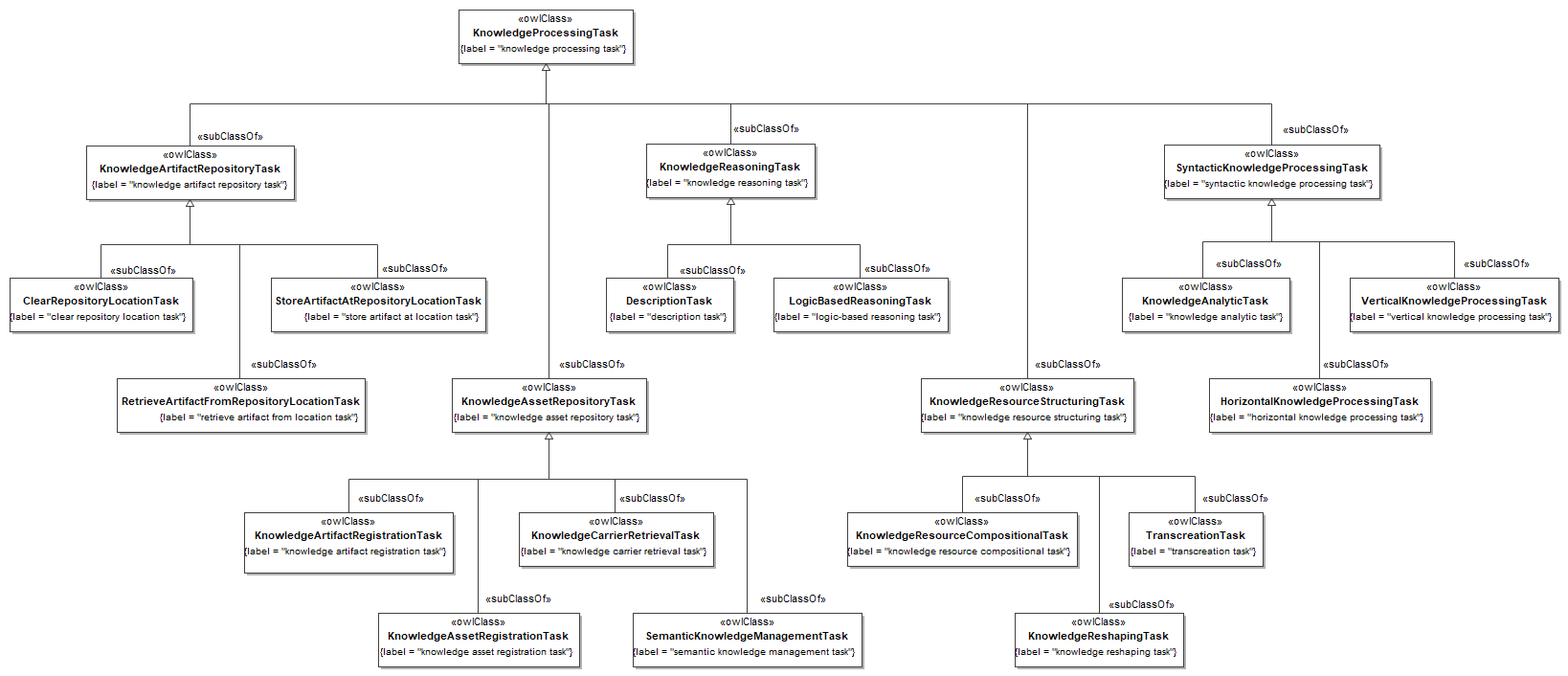
- (b) We have rebuilt the model using a more parsimonious approach. Interfaces, inheritance and constraints have been removed, as they turned out not to be necessary for the goal at hand, and would have not been supported by the downstream implementations. We have taken an even more radical approach, limiting the model to the use of primitive and structured datatypes, with no classes nor operations. The rationale behind this choice is that the API4KP datatypes do not represent identifiable Resources, and do not capture behavior themselves (i.e. they are not "objects"), but rather data structures used to describe, wrap or support operations on Knowledge Resources. As a side effect, this sober modeling approach is more likely to be universally mappable
- (c) We have performed a retrospective analysis of the 5year long implementation at Mayo Clinic, which has led to 12+ server implementations of the 5 API4KP service interfaces, and 30+ implementations of the API4KP atomic operations, as well as the extrapolation of the methodology to other APIs beyond API4KP. We have looked at PSM options - namely Java, C# and JavaScript, on local VMs, the Spring Framework on a Web Application Server, Azure Function Apps and Google Cloud Functions. We have looked at emergent standards and best practices, including but not limited to JSON APIs, JSON-LD, SPARQL API, CloudEvents and the FHIR paradigm in healthcare.
We have used this experience to synthesize a new, revised datatype model that is coherent with the original intent, compatible with the APIs, and known to have at least some degree of practical utility
- (d) We have improved the documentation
After the major revision, we have
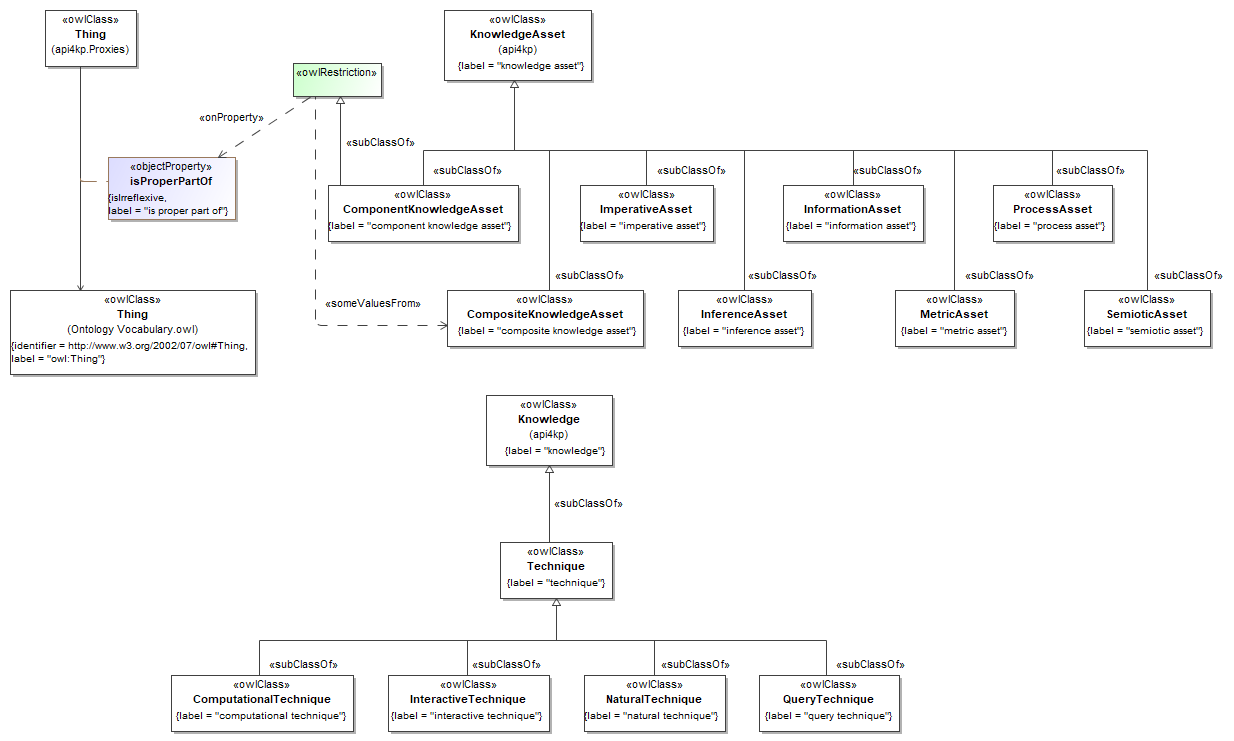
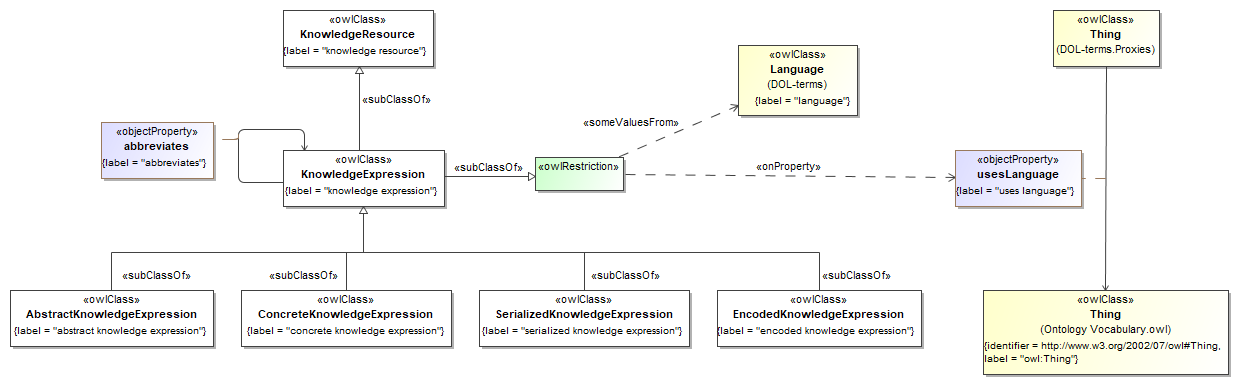
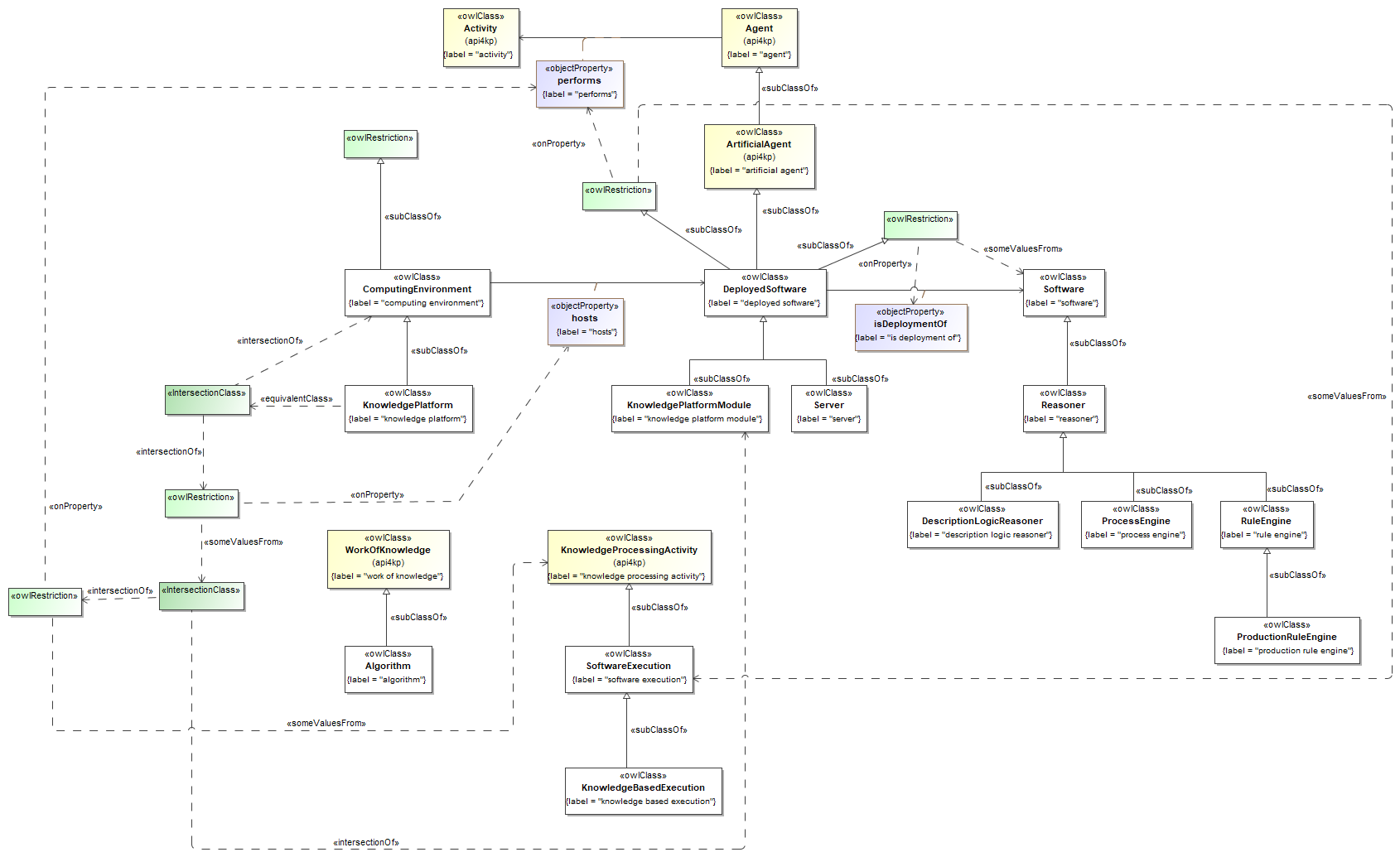
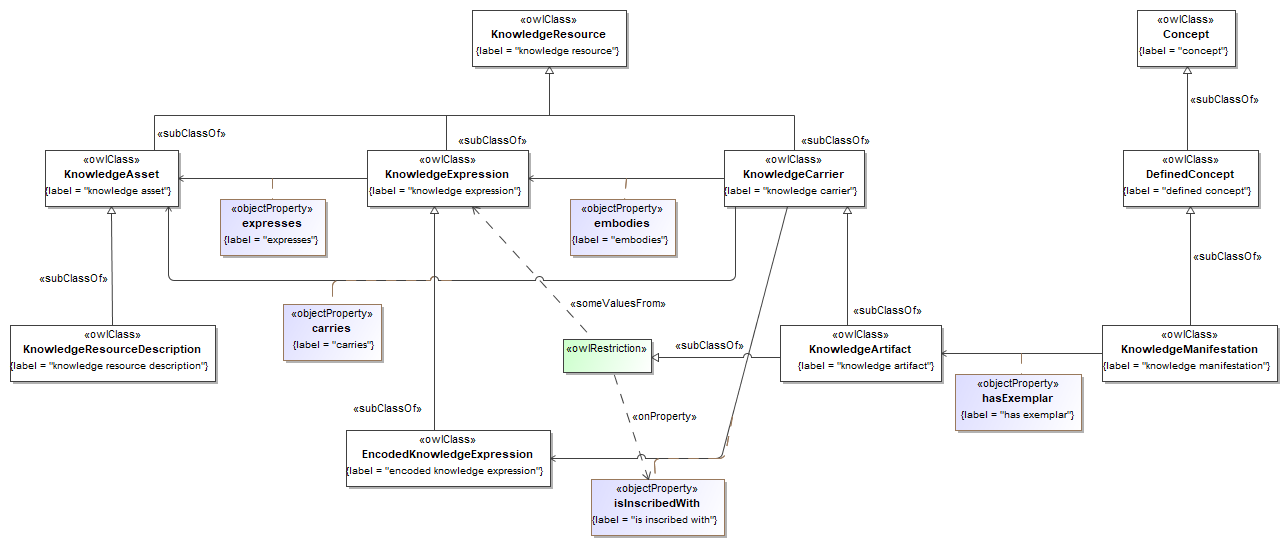
- produced a completely revised UML/XMI model, which preserves the original 5 packages
- "datatypes", for primitive datatypes
- "id", for identifiers, references and other designators
- "services", for the "wrappers" used in the API runtime layer
- "descriptors", to include service manifests used for capability statement and discovery
- "surrogate", to provide a shape for semantic metadata about Knowledge Resources
- regenerated the derivative models:
- XSD schemas
- OpenAPI schemas (JSON schemas in YML format)
- IDL struct definitions
- revised the API spec documentation, where the changes impacted Chapter 7, from section 7.2.1 to section 7.2.9 excluded
- revised the API specs themselves, updating the operations as follows:
- KnowledgeAssetRepository
- replaced all occurrences of return datatypes "CompositeKnowledgeCarrier" with "KnowledgeCarrier",
- replaced the return type of 'queryKnowledgeAssetGraph', from "Bindings" to "QueryResults"
- Transrepresentation
- consolidated all occurrences of return datatypes "Transrepresentator", "Detector", "Validator", "Deserializer" with "KnowledgeProcessingServiceManifest"
- consolidated all occurrences of return datatypes "TransrepresentationOperator", "DetectionOperator", "ValidationOperator", "DeserializationOperator" with "KnowledgeProcessingOperator"
- KnowledgeReasoning
- removed the declaration of the datatype 'Map', undefined and not used
- replaced "Bindings" with "QueryResults" as the return type of the "askQuery" operation
Attached, find:
- the preview of the revised documentation, scoped to the impacted sections only (due to size limitations)
- the API4KP spec document changelog, which reports the changes to the document with respect to the original document
- the revised UML/XMI model (api4kp.mdzip)
- a ZIP file containing the derived schemas
- a ZIP file containing the UML diagrams for the revised model
Final remark:
The original datatype model proposed a custom way to bind some datatype elements to "ValueSets" - open enumerations derved from Concept Schemes,
in turn derived from specific sub-trees of the API4KP ontologies. This subject has emerged in other specifications being developed - MVF, SCE, PPMN and KPMN to name a few.
This mechanism was overused in the original and revised submissions of API4KP, and the SKOS bound enumerations did not turn out to be completely satisfactory.
Enumerations are usually 'closed', and not all PSM support complex enumerations; while OWL -> SKOS mappings are fairly common, there is not a single canonical approach.
Moreover, trying to enforce a semantic constraint at the schema syntax level is arguably an incoherent approach.
Given these cosiderations, we have decided do abandon the approach altogether, Instead of Enumerations, we have introduced a more generic ContnrolledTerm datatype,
which consists of a label and a URI that can be used to reference semantic entities such as Concepts.
The (semantic) constraints in the schema are not required to use and/or implement the APIs, so this should not be considered a limitation.
Moreover, we have not abandoned the goal, and will propose a different approach, which needs more discussion and is likely to have a dependency on the MVF standard.
This enhancement will be deferred to a later time.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}